从MapReduce开始
RDD(Apache Spark)——MapReduce的继任者
(Resilient Distributed Dataset)

RDD特点
- 只读且被分区的数据集
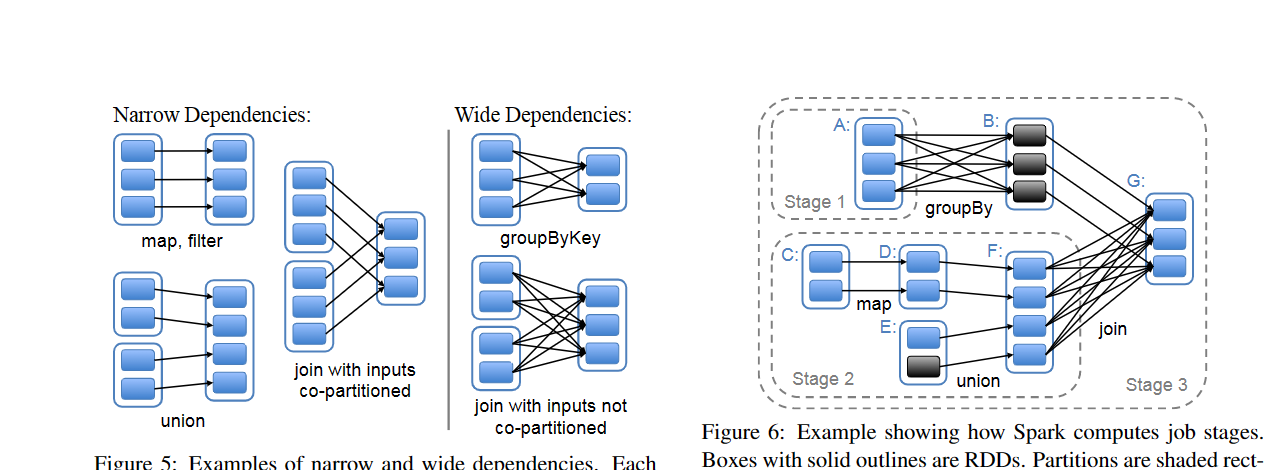
transformation操作:通过存储系统和其他的 RDDs 进行操作而创建一个新的 RDD,如map,filter以及join等- 不同的算子对应不同的依赖关系,宽依赖与窄依赖
从Scala到Rust,从Maven到Cargo
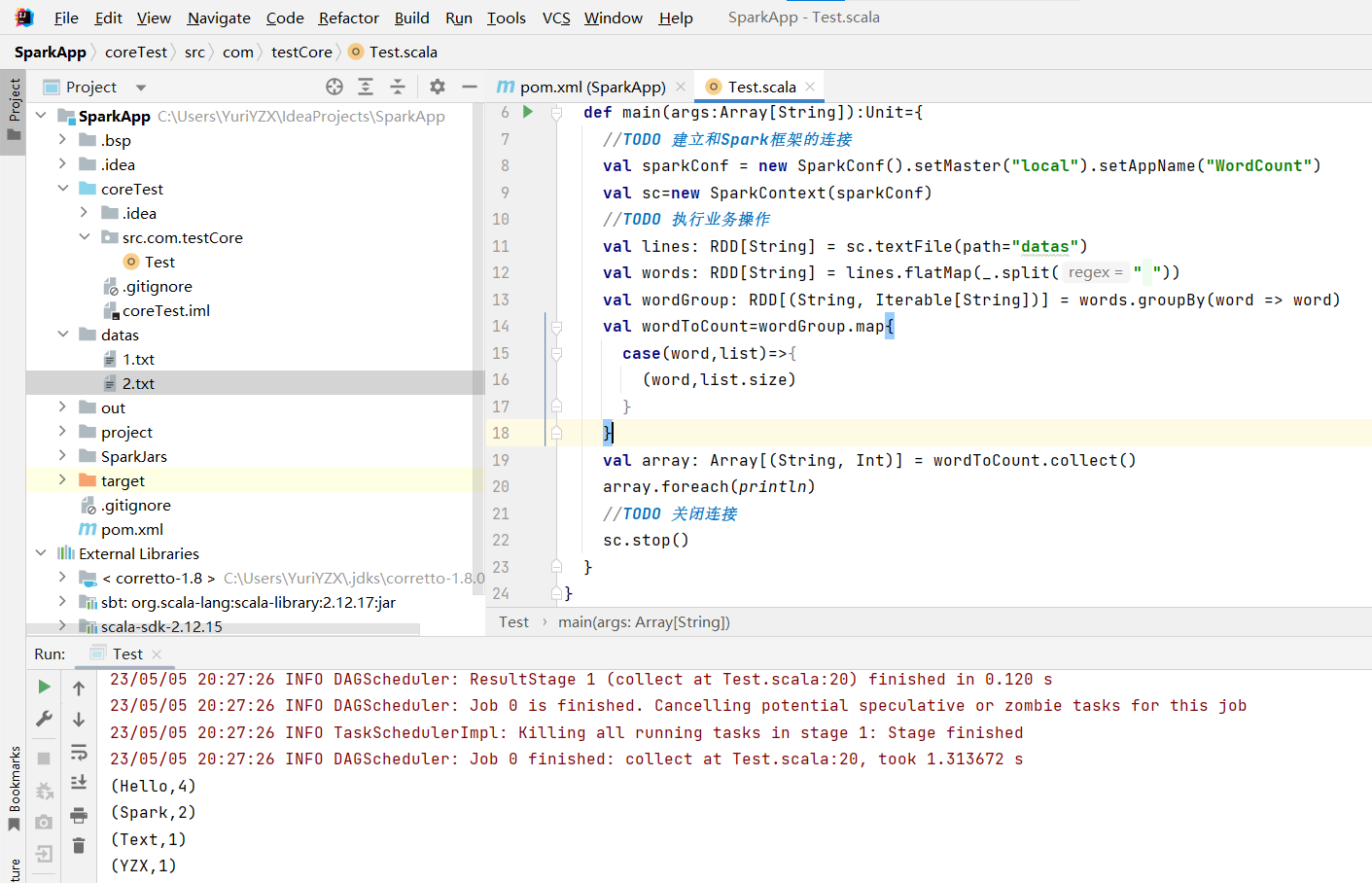
Rust与Scala通过JNI交互

- Scala是在JVM上运行的语言,常用JNI接口与C语言等实现交互。
- 另一方面,Rust可通过二进制接口的方式与其他语言进行交互。
jni crate对JNI提供了安全的Rust接口。
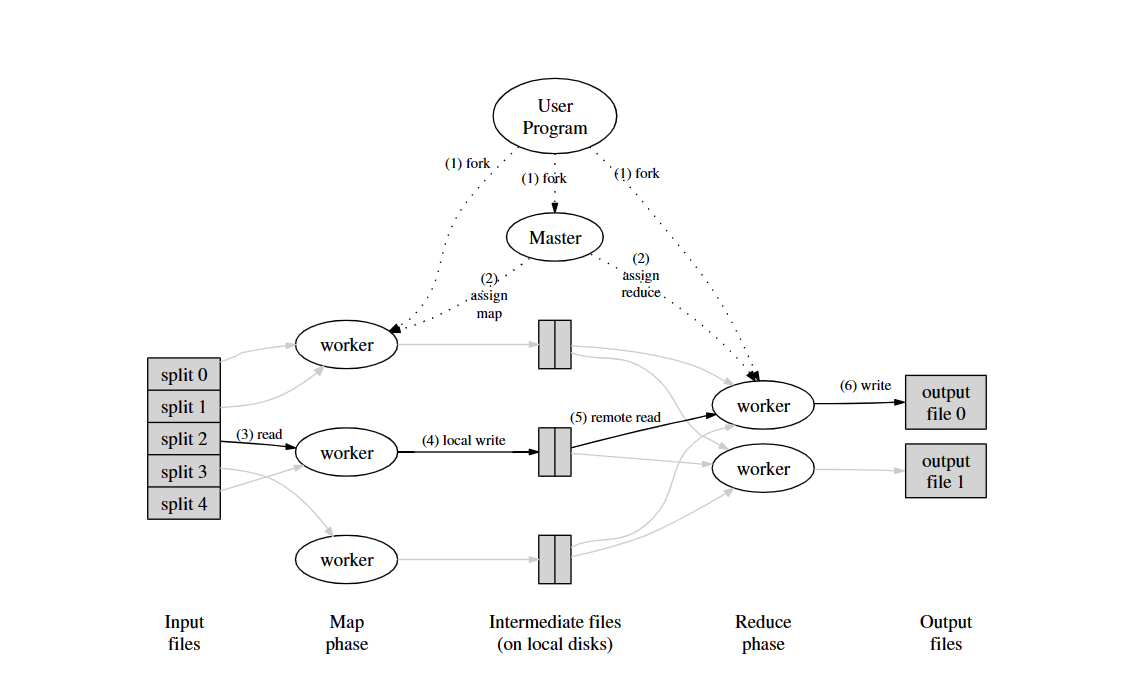
DAG调度
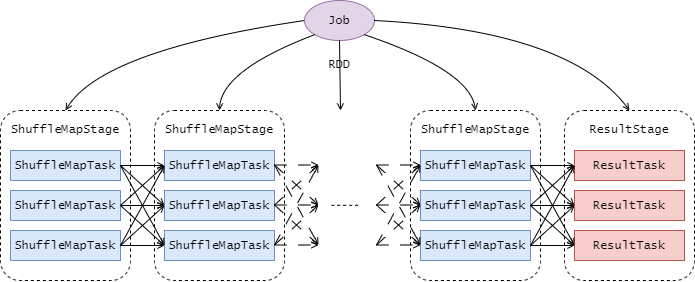

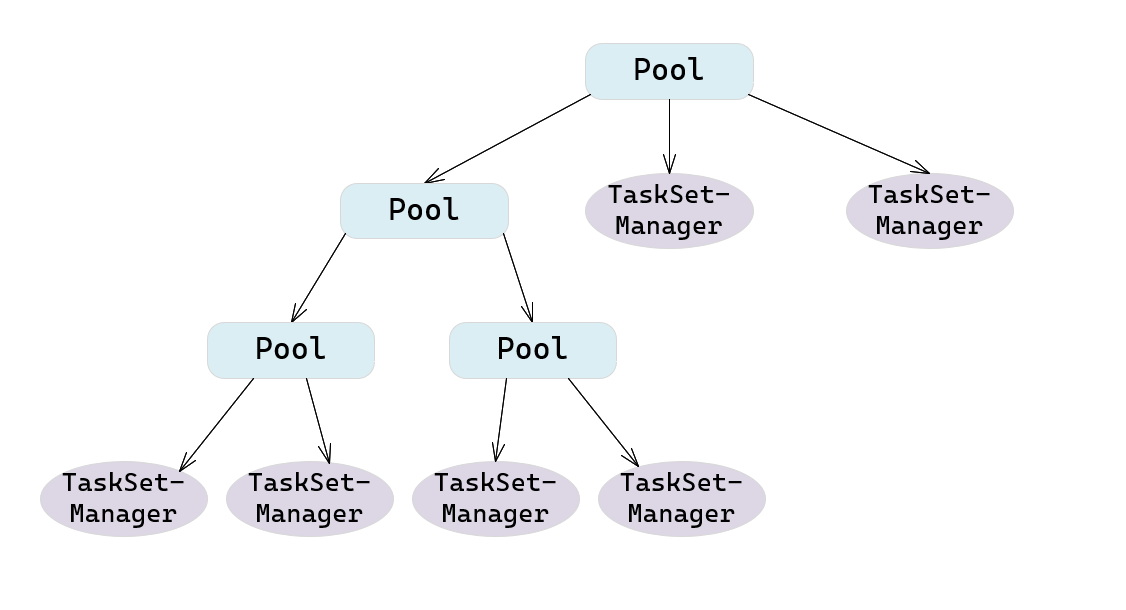
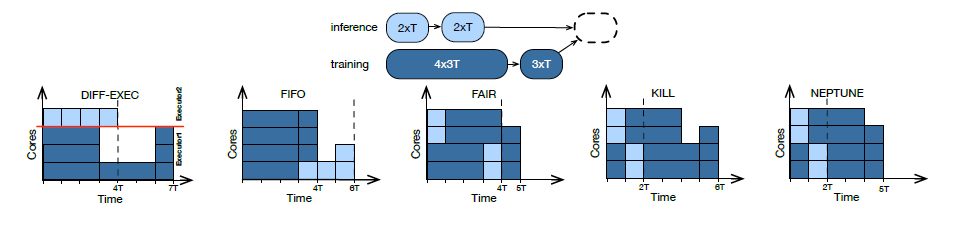
Spark Streaming内部组件
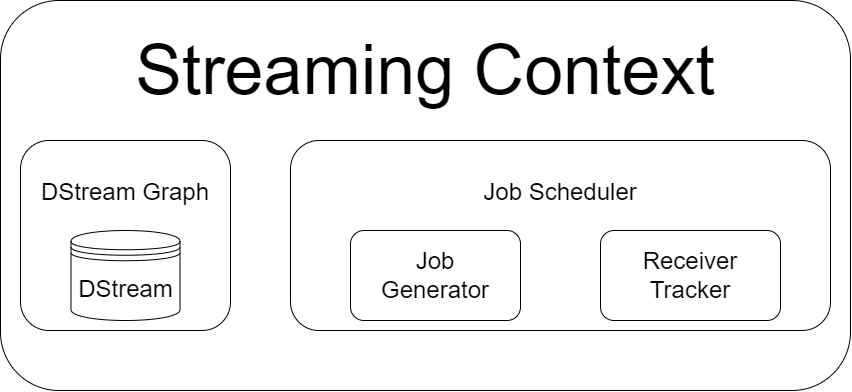
Streaming Context:Spark Streaming的起始点和上下文
DStream和DStream Graph:封装流式数据和依赖关系
JobScheduler和ReceiverTracker:调度,生成作业,控制Receicer状态
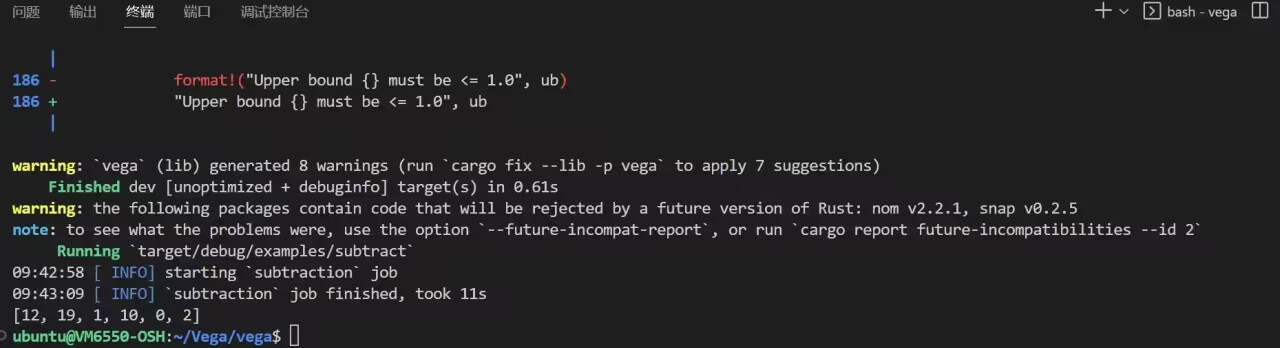
Spark build
vega build
vega build