基于Rust版Spark开源项目vega
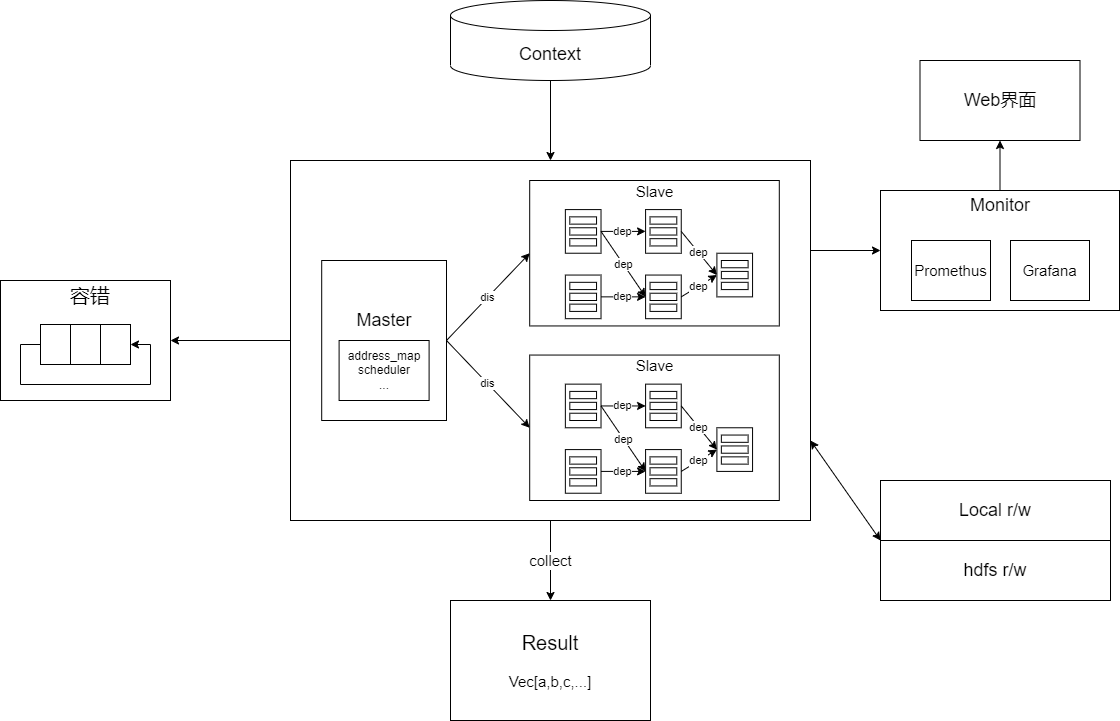
项目架构
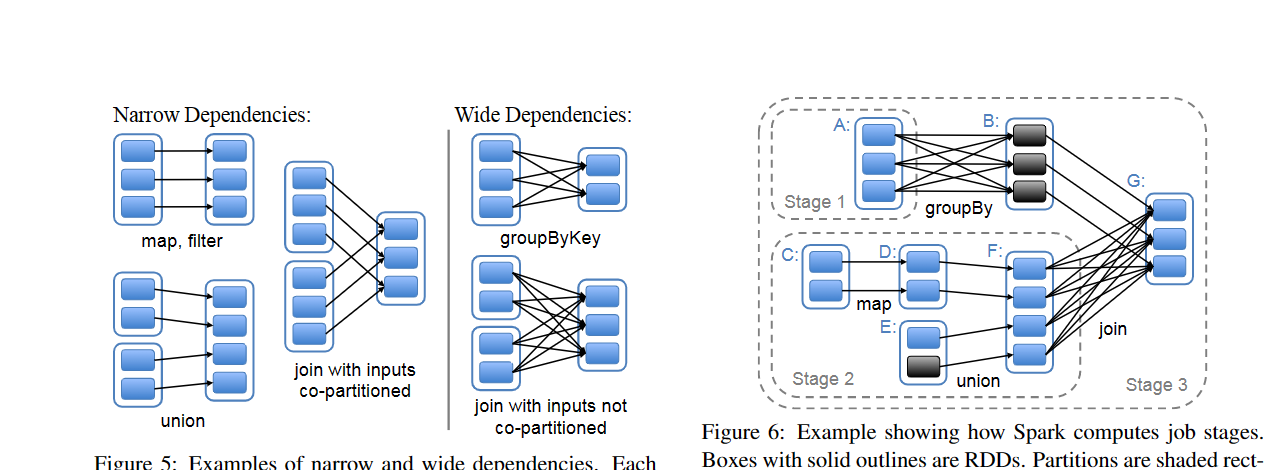
Spark和RDD
改进依据
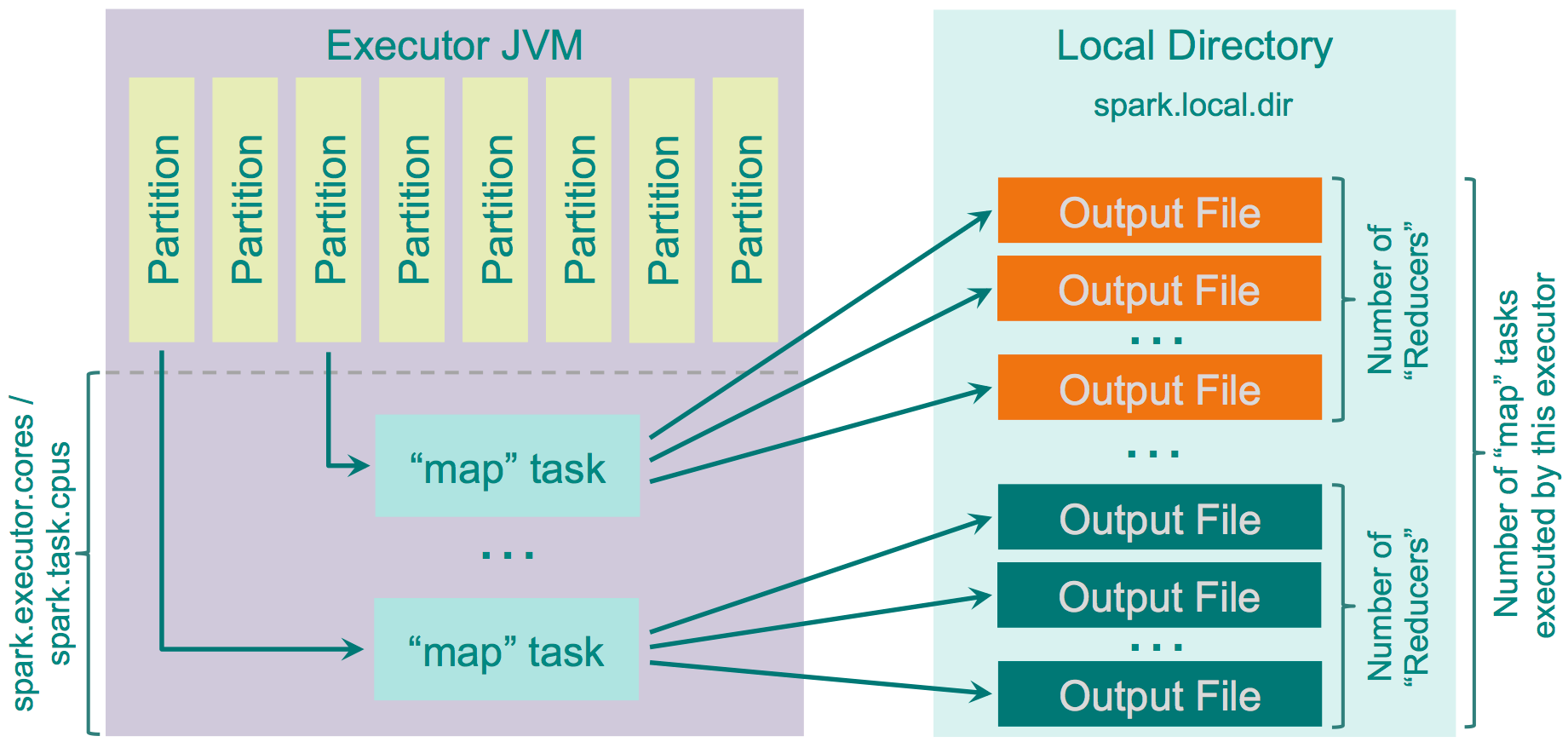
Hash Shuffle Manager
- 对每一对Map和Reduce端的分区配对都产生一条分区记录,原版Spark生成一个文件存入,Vega将Shuffle记录保存在以DashMap(分布式HashMap)实现的缓存里
- 由于生成的文件数过多,会对文件系统造成压力,且大量小文件的随机读写会带来一定的磁盘开销,故其性能不佳
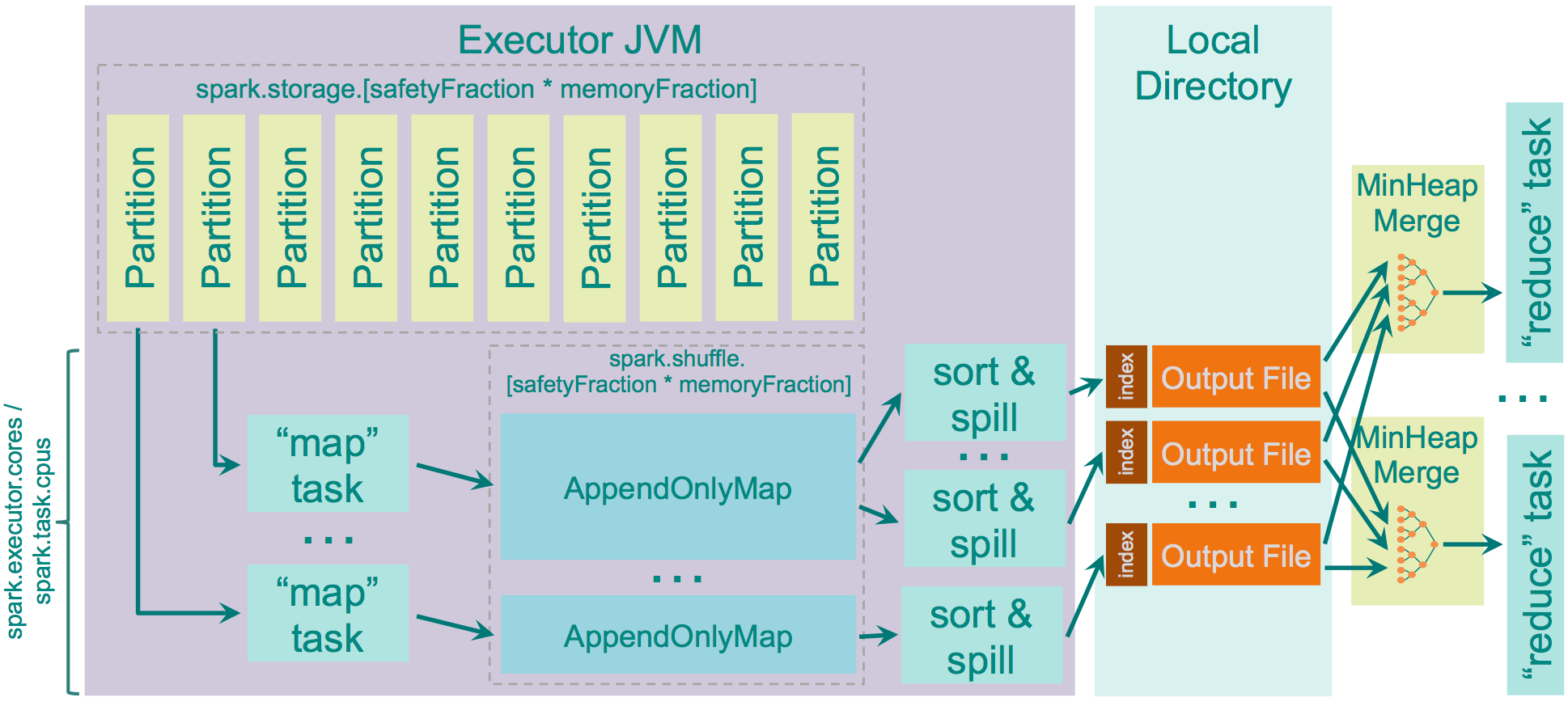
Sort Shuffle Manager
- 数据会根据目标的分区Id(即带Shuffle过程的目标RDD中各个分区的Id值)进行排序,然后写入一个单独的Map端输出文件中,而非很多个小文件
- 输出文件中按reduce端的分区号来索引文件中的不同shuffle部分
- 大幅减小了随机访存的开销与文件系统的压力,不过增加了排序的开销
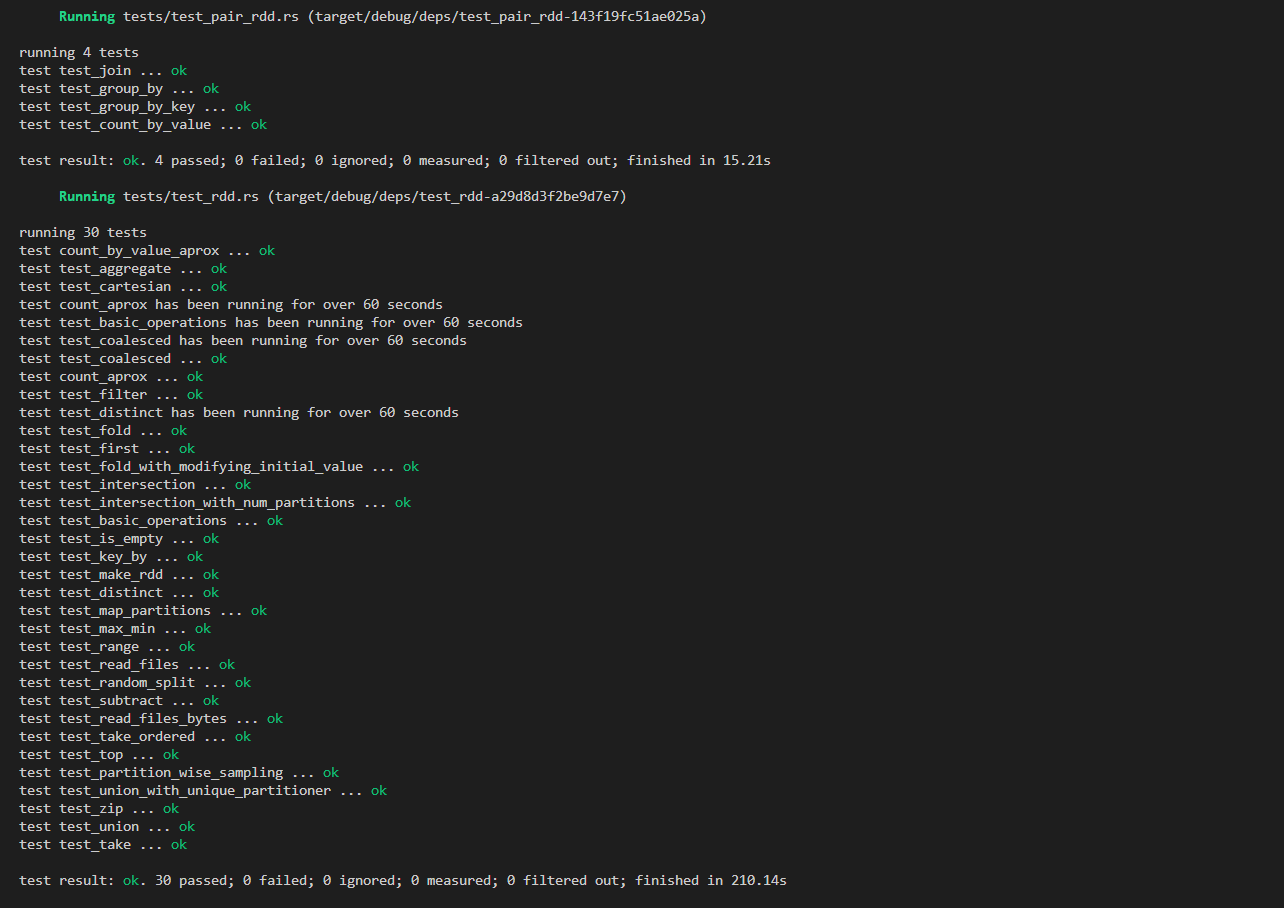
Shuffle优化测试结果
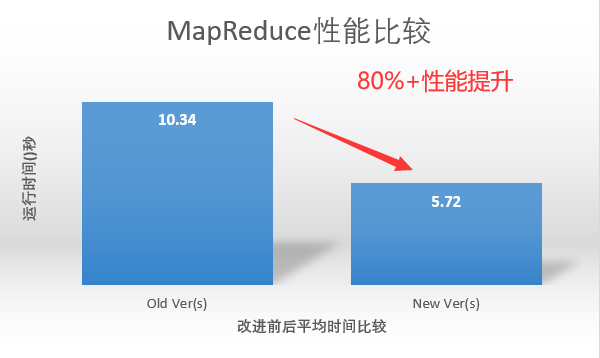
使用两千万条shuffle记录的载量进行单元测试,测试结果如下:
(Map端有M个分区,Reduce端有R个分区,$M\cdot R=20000000$)
| 时间/s | 1 | 2 | 3 | 平均 |
|---|---|---|---|---|
| 优化前 | 9.73 | 10.96 | 10.32 | 10.34 |
| 优化后 | 6.82 | 5.46 | 4.87 | 5.72 |
运行速度提升了81%
VEGA原来的容错情况
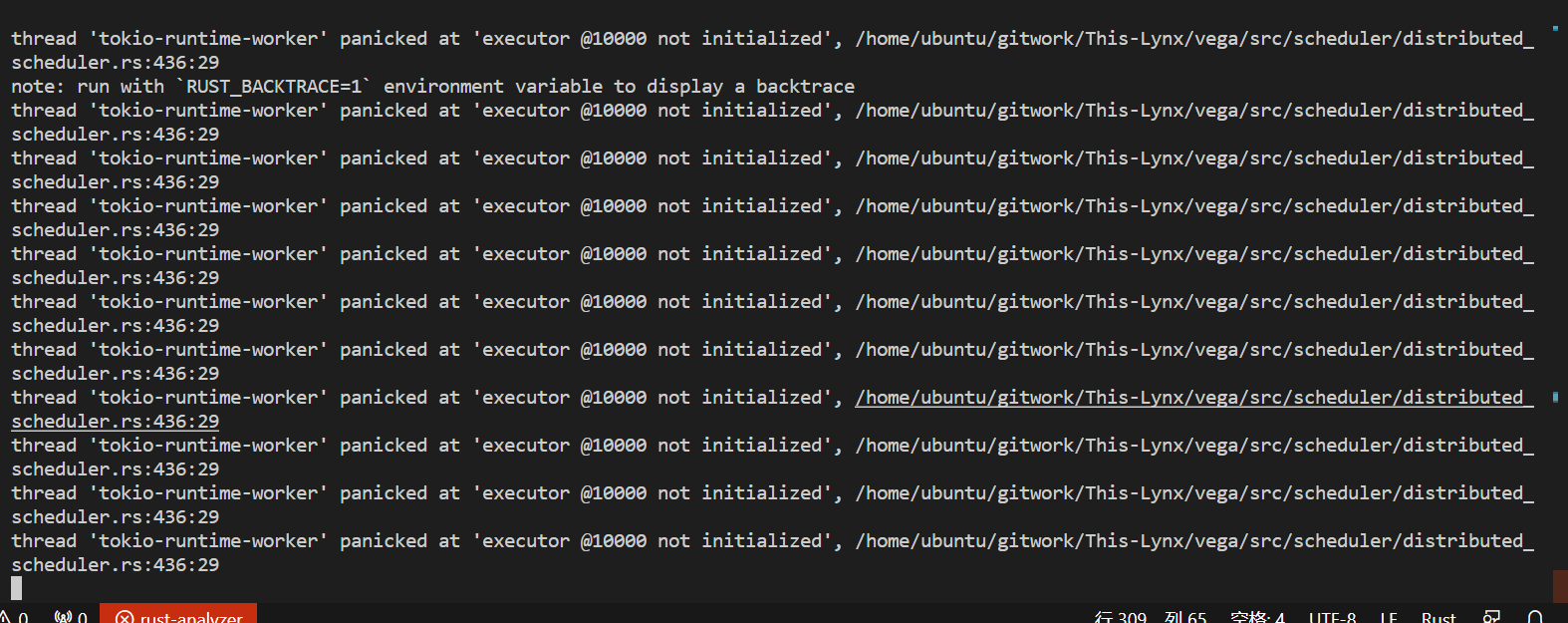
容错机制
利用循环队列,在某从机下线时递归地进行任务的重新分发,
保证程序的正常运行,并打印出相关Error信息以供用户检查。

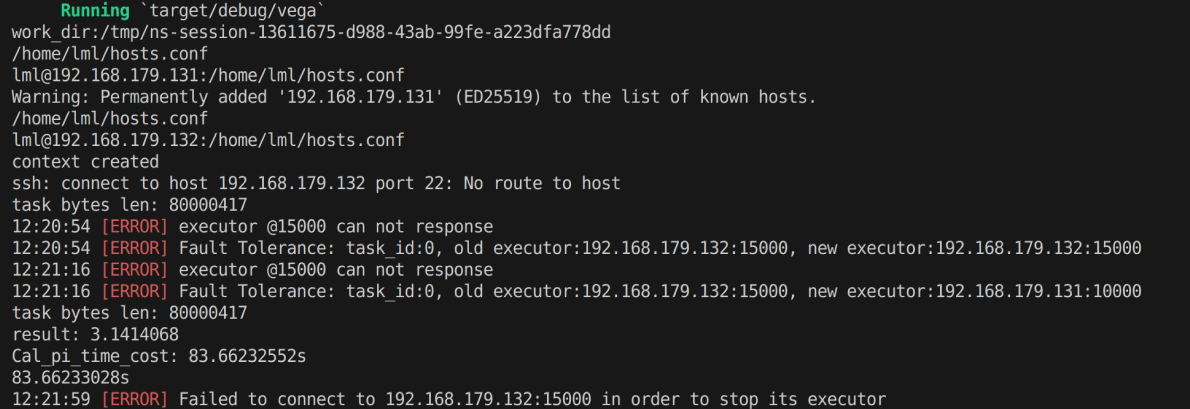
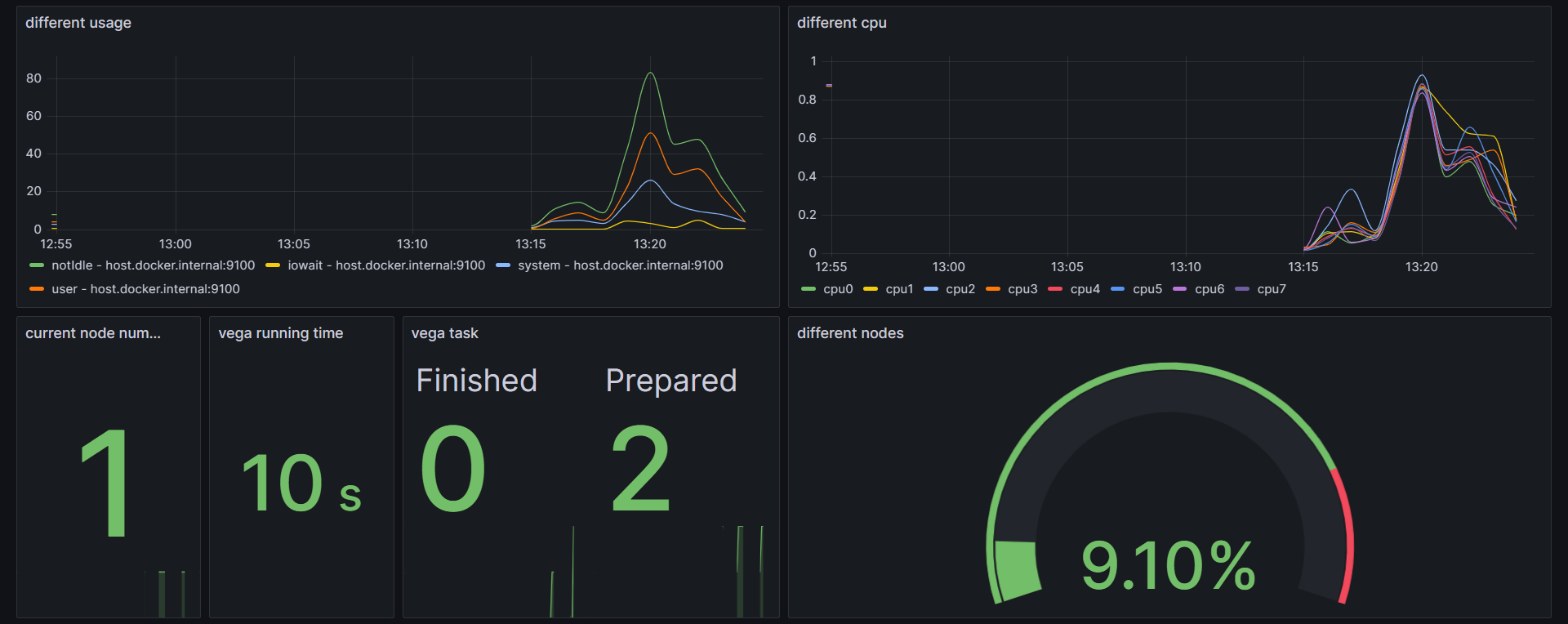
效果展示
Hdrs
- 用Rust包装HDFS的C接口
- 实现了Read、Write等Trait,功能丰富
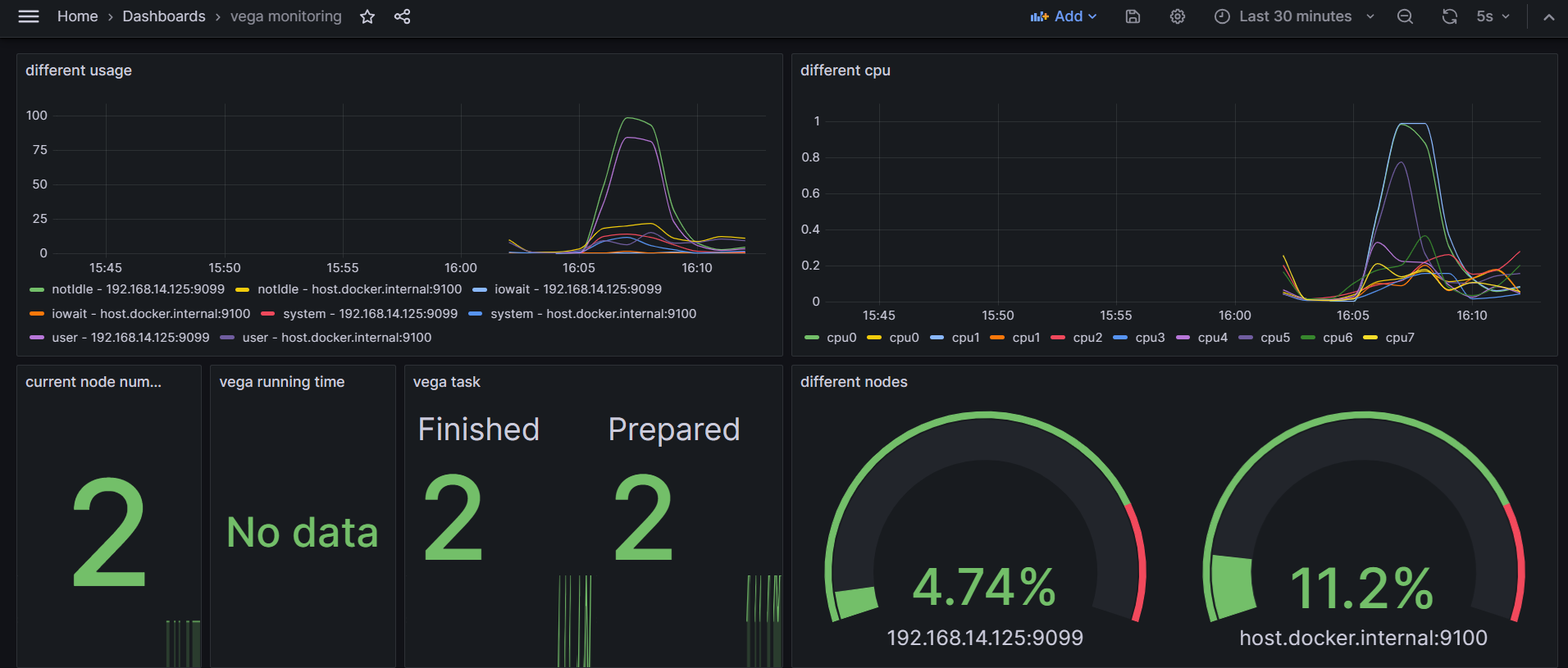
效果展示
效果展示
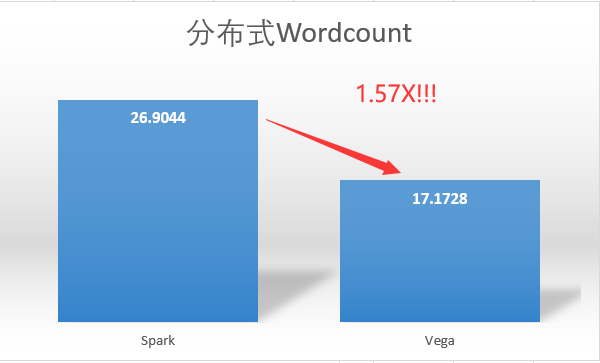
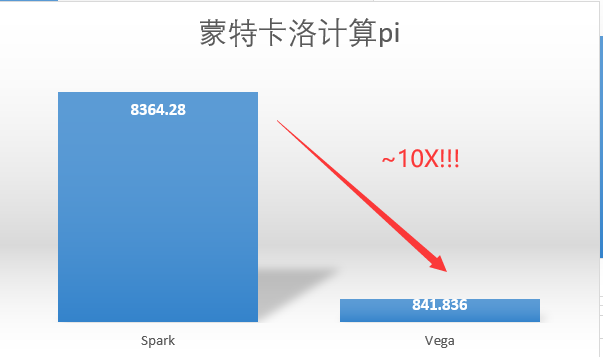

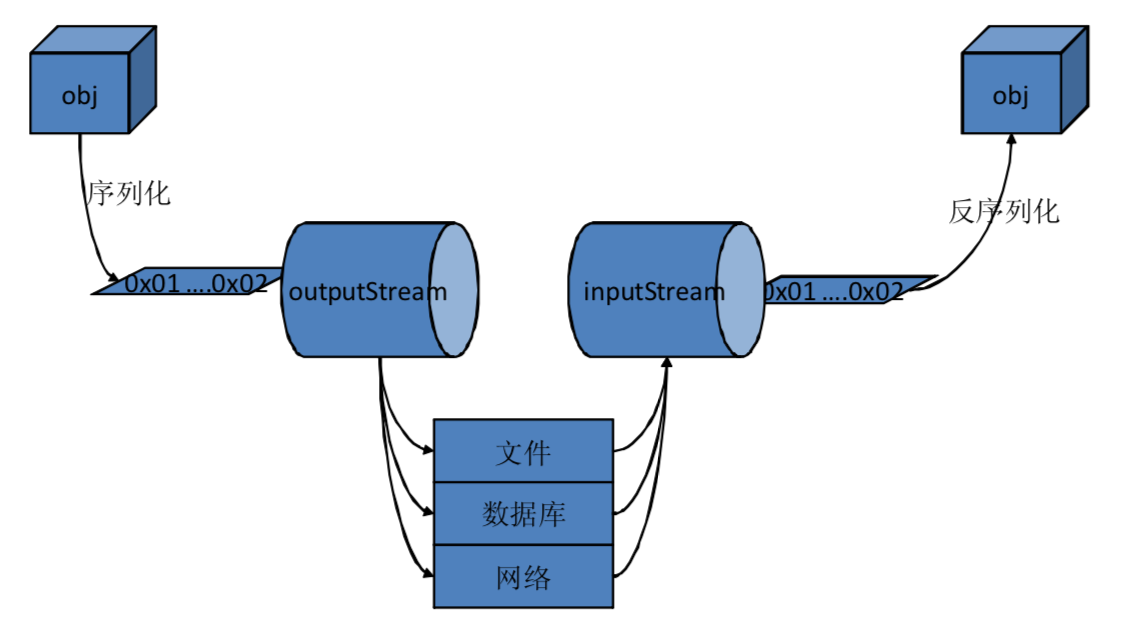
减少序列化反序列化开销
构建更加用户友好的API
- Rust的类型机制较为复杂
- 原有的RDD算子类型不够丰富