3-26 正式立项讨论
在分布式系统下一些可行方向
- 基于2004年google提出的Mapreduce上的hadoop和spark
- paxos算法到raft协议
- ray 和 ceph
- 使用rust改进spark框架
- GFS 对象存储
确定方向
~~使用已有的分布式文件,任务调度等系统,基于mapreduce对分布式计算框架进行改进。~~(已被否)
rust重写Spark
- 创新性:原生Spark使用Scala实现,Scala 是一种支持函数式编程的高级编程语言,但是rust作为一种系统编程语言,相较于Scala具有内存安全性的特点,同时运行速度可以与C语言相比,很适合编写高性能,安全的系统及代码。
- 可行性:清华大学操作系统课程用rust实现了教学操作系统rCore,在2022级x-realism小组中实现了rust重写内核的工作,加之rust有活跃的社区以及完整的文档,语言本身可以快速入门。另外Spark作为Apache下的开源顶级项目,可以轻松的查阅源码实现。
- 重要性/前瞻性:目前Rust社区处于快速发展迭代的黄金时期,用其作为工具实现分布式计算系统框架具有乐观的发展前景。
- 工业/学术前沿(背景): http%3A//spark.apachecn.org/paper/zh/spark-rdd.html
Spark解决了已有框架,如MapReduce对于迭代式算法场景和交互性数据挖掘场景的处理性能差,RDDs的概念提供了高效的容错方式并且很好的支持了流式数据处理的问题。 ### 寻找瓶颈模块
为C语言实现垃圾回收器(GC)并复现OSDI 2022 best paper[^1]中的GC优化思路。
- 创新性:
- C语言由于其手动分配内存/释放内存的繁琐工作而臭名昭著,为其编写垃圾回收器大大减轻了管理内存的负担,同时用户保留了手动分配内存的自由。
- 论文中提到的新的在垃圾回收机制上通过改变访存顺序的优化办法可以提高对远程内存使用的效率平均1.5x~2x
- 可行性: github上有一个简单实现GC的开源项目,仅仅实现了最简单的标记-清除算法,原始代码量在2k行上下。 MemLinear论文将项目开源在github上,优化了JVM的垃圾回收器,相较于G1 GC和Shenandoah GC有显著提升。
- 重要性/前瞻性: C语言缺少垃圾回收器的弊病由来已久,增加GC实现影响重大,另外考虑垃圾回收机制作为当前高级语言的普遍机制,以及其作为拖累分布式系统中的远程内存共享效率的重要瓶颈,在广泛的应用场景下对其优化有显著意义。
- 工业学术前沿:OSDI 2022 best paper,够前沿了吧。 论文中观察到1.Application和GC的内存访问只是在时间上不一致,但对存活对象的访问是一致的2.改变GC的内存访问顺序并不会影响其正确性,提出了优化访问顺序的基本思路: [^1]:《MemLiner: Lining up Tracing and Application for a Far-Memory-Friendly Runtime》 已知调研报告需要包括:项目背景、立项依据、前瞻性/重要性分析、相关工作
使用rust实现基于GFS的分布式文件系统
- 创新性:基于GFS或在其基础上改造的分布式文件系统有很多,如HDFS,MooseFS等,但使用Rust实现的目前还没有。Rust具有高性能且安全性强的特点,可以为分布式文件系统提供更好的安全性和性能的保证。
- 可行性:GFS本身不开源,但其实现思路在论文中描述的很清楚,且有很多参照GFS实现的开源项目。鉴于20年也有用rust重写分布式文件系统的项目,Rust实现GFS应该具有可行性。
- 重要性/前瞻性:分布式文件系统是满足现有海量信息存储需求的重要手段。用Rust实现有助于进一步满足对分布式文件系统在安全性和性能方面的需求。
- 工业/学术前沿:HDFS,MooseFS等基于GFS的分布式文件系统现在仍在得到广泛应用,这说明GFS在很多方面仍能满足当前的需求(例如适合大文件和大量追加写入等)。
基于GFS的分布式对象存储系统(待定)
- 创新性:GFS本身并不是对象存储,目前基于GFS的分布式存储系统(如HDFS,MooseFS)也几乎都不是对象存储的。
- 可行性:基于GFS的开源存储系统有很多,开源的分布式对象存储系统也有像Ceph这样的项目,参照它们的源码结合两者的特点应该具有可行性。
- 重要性/前瞻性:对象存储有利于处理海量的非结构化数据,如音频、视频、图像等,这类数据往往较大,且通常不会随机写入,恰好与GFS的特点相适应。
- 工业/学术前沿:根据GFS的特点,我们预测基于GFS的分布式对象存储系统将具有适合大量顺序读取和(顺序)追加写入,极少随机写入,且读取多于写入的场景,且具有很强的可靠性。这样的特性非常适合音视频平台使用。
数据混合批处理和流处理框架
- 创新性:流处理框架和批处理框架都有其各自的优势,但是在实际应用中,往往需要同时使用这两种框架,但是这两种框架的数据处理方式不同,需要在两种框架之间进行数据转换,这样会增加系统的复杂度,同时也会增加系统的开销。因此,我们希望能够设计一种数据混合批处理和流处理框架,使得系统能够同时使用批处理和流处理框架,而不需要进行数据转换。
- 可行性:动态调度,优先处理流数据达到低延迟,同时处理批数据达到高吞吐。利用微批次的思想,考虑数据本身特点和数据的速率,对数据进行分割。
- 重要性/前瞻性:参考论文[^2][^3] [^2]:Panagiotis Garefalakis, Konstantinos Karanasos, and Peter Pietzuch. 2019.Neptune: Scheduling Suspendable Tasks for Unified Stream/Batch Applications. In ACM Symposium on Cloud Computing (SoCC ’19), November 20–23, 2019, Santa Cruz, CA, USA. ACM, New York, NY, USA, 13 pages.https://doi.org/10.1145/3357223.3362724 [^3]:Ahmed S. Abdelhamid, Ahmed R. Mahmood, Anas Daghistani, Walid G. Aref. 2020. Prompt : Dynamic Data-Partitioning for Distributed Micro-batch Stream Processing Systems. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (SIGMOD’20), June 14–19, 2020, Portland, OR, USA. ACM, New York, NY, USA, 15 pages. https://doi.org/10.1145/3318464.3389713
基于分布式计算的实时导航系统
- 创新性:
- 该选题本身是暂未实现的。
- 该选题所基于的spark等分布式计算系统,可能需要进行融合与优化,才能更好地适应该问题。
- 该选题虽然基于最短路径问题,但是与传统的最短路径问题存在差别与可优化的地方。
- 可行性:
- spark等分布式计算框架已具有良好的生态,便于搭建分布式计算系统,前人也有许多基于spark的项目开发经验可以借鉴。
- spark自身也可兼容pregel图计算框架等,另有spark streaming这种应对流处理问题的版本,通过对他们的结合,可能较好地满足既定的需求。
- 本问题是基于最短路径算法的一种延伸,而最短路径算法作为一个历史悠久的问题,已有充足的研究积淀。
- 重要性/前瞻性:当今的导航系统大多没有实时导航的功能,而现实中路况千变万化,仅仅依靠出发时确定的路线可能无法适应用户的需求。(该功能可以作为用户的可选设置项)
- 初拟思路与挑战:
- 可将整个问题分解为建立合适的数据结构与查询两个步骤。
- 要求能够根据路况实时更新数据结构,要求更新的时间尽量短(尽量在1~2秒内,防止延误查询),且尝试让数据结构的大小尽量小(如O(lgn))。
- 要求查询的时间尽量短(尽量在1~2秒内),并以较高概率(1-o(1))返回最短路径/最短时间/最短距离/当前最优的下一目的节点。
- 如果查询的时间超过常数级别,是否可以优化并做到并发的查询。
- 重要性/前瞻性:参考论文[^4][^5] [^4]:Gallo, G., Pallottino, S. Shortest path algorithms. Ann Oper Res 13, 1–79 (1988). [^5]:Stuart E. Dreyfus, (1969) An Appraisal of Some Shortest-Path Algorithms. Operations Research 17(3):395-412.
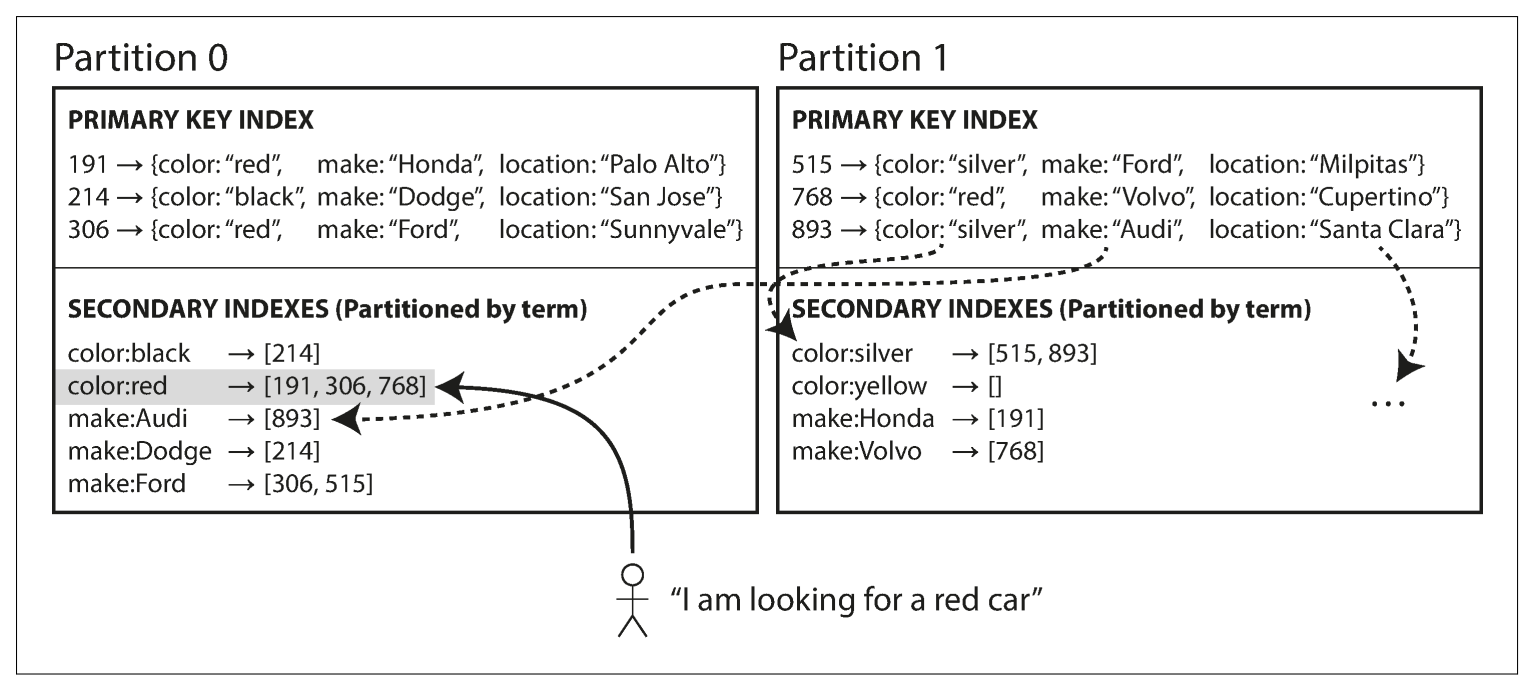
基于全局词条分区二级索引的分布式数据系统
- 背景及项目介绍:我们将基于教务系统选课模块的应用场景实现一个基于全局词条分区二级索引的分布式数据系统。我们知道教务系统选课模块、评课社区等应用场景都具有典型的写入负载小、查询负载大的特点,它们在平时只处理少量读写请求,而在选课的时间点附近要处理极高并发的读请求,而基于的词条分区的二级索引技术正好是一种以存储空间和写入速度为代价大幅优化查询速度的方案,它在构建索引项(涉及查询条件的,如课程名、任课老师)时开销较大,但在改变选课人数这样的非索引项时写开销小,读开销则会被优化得很小。同时,此技术专门用于适配分布式系统,可以令多台主机合力处理用户请求,非常适合在这种应用场景下使用。此系统应能够支持在运行过程中增减服务器节点数量,从而可以在高峰期增加节点数,日常提供服务时减少节点数。
- 创新性:由于二级索引不符合数据库正则化的要求,所以许多数据库不支持,而全局的二级索引更是实现得很少,但它确实在选课这样的场景中有很显著的优势,我们希望能实现这样一个分布式数据系统,专门解决选课等应用场景的问题,并将基于此进行模拟测试。
- 可行性:可行性主要有以下的考虑:
- 构建一个分区的数据库需要诸多技术,如分区方案、分区再平衡、维护分区到节点的映射等,以及更加底层的网络技术等的实现
- 需要完善的二级索引技术,保证增删改下数据库及索引的正确性,还要保证其在整个分布式系统中的一致性
- 对于每门课选课人数及名单这种实时变化极快且一致性要求极高(不能出现超出课堂容量等情况)的数据,应当有高鲁棒性的一致性算法实现
- 最好需要有访问流量监控等运维工具加持
- 重要性/前瞻性:相信大家都体会过选课期间教务系统的卡顿与崩溃,一定明白优化教务系统对读请求处理的优化是极为重要的、与全体科大学子的学习生活息息相关的,这体现了我们项目的重要性
调研报告的分工
[ ] 文件系统 - 李牧龙
[ ] 任务调度 - 汤皓宇
~~[ ] mapreduce原理+RPC - 闫泽轩~~
[ ] 一致性算法 - 罗浩铭
[ ] 不同分布式计算框架的区别 - 徐航宇
下周4月2日开会